Brief Notes on 6.824 Lab 1
Brief notes on my implementation of 6.824 Lab 1.
Background
Big data processing lacked an effective paradigm until Google published MapReduce in 2004, which introduced the classic map and reduced concepts from functional programming into the field of big data processing. The introduction of this concept greatly simplified the process of data processing, making it possible to process various data in a unified way. Although nearly twenty years have passed, the processing of big data has made great progress, but MapReduce is still an important starting point for us to understand distributed systems.
In functional programming, map and reduce are two very classic functions for processing arrays. For example, in JavaScript and Rust, we can use them to build new arrays or sum them up:
JavaScript
const array = [1, 2, 3, 4]
const map_res = array.map((x) => x * 2)
console.log(map_res)
// [2, 4, 6, 8]
const reduce_res = array.reduce((acc, x) => acc + x, 0)
console.log(reduce_res)
// 10Rust
let a = [1, 2, 3, 4];
let map_res = a.iter().map(|x| x * 2).collect::<Vec<i32>>();
println!("{:?}", map_res);
// [2, 4, 6, 8]
let reduce_res = a.iter().fold(0, |acc, x| acc + x);
println!("{}", reduce_res);
// 10For larger-scale data, the data to be processed can always be constructed as {Key: Value}, and then map and reduce can be used to process the data. For example, we can count the occurrences of words in an article:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
result = 0
for each v in values:
result += ParseInt(v)
Emit(AsString(result))
// See "MapReduce: Simplified Data Processing on Large Clusters"The function of this pseudo-code is straightforward: First, we split the document into words and generate an intermediate product of many <word> 1. Then, we aggregate the intermediate product and get the word count result.
Based on this paradigm, MapReduce designed a framework for distributed execution, which includes a management node (Master) and multiple Worker nodes (Worker). In the two stages of the entire execution (Map and Reduce), the Master assigns the tasks to be executed to the Worker, and the Worker returns the results to the Master after completing the tasks. Finally, the Master summarizes the results of all Workers to obtain the final result.
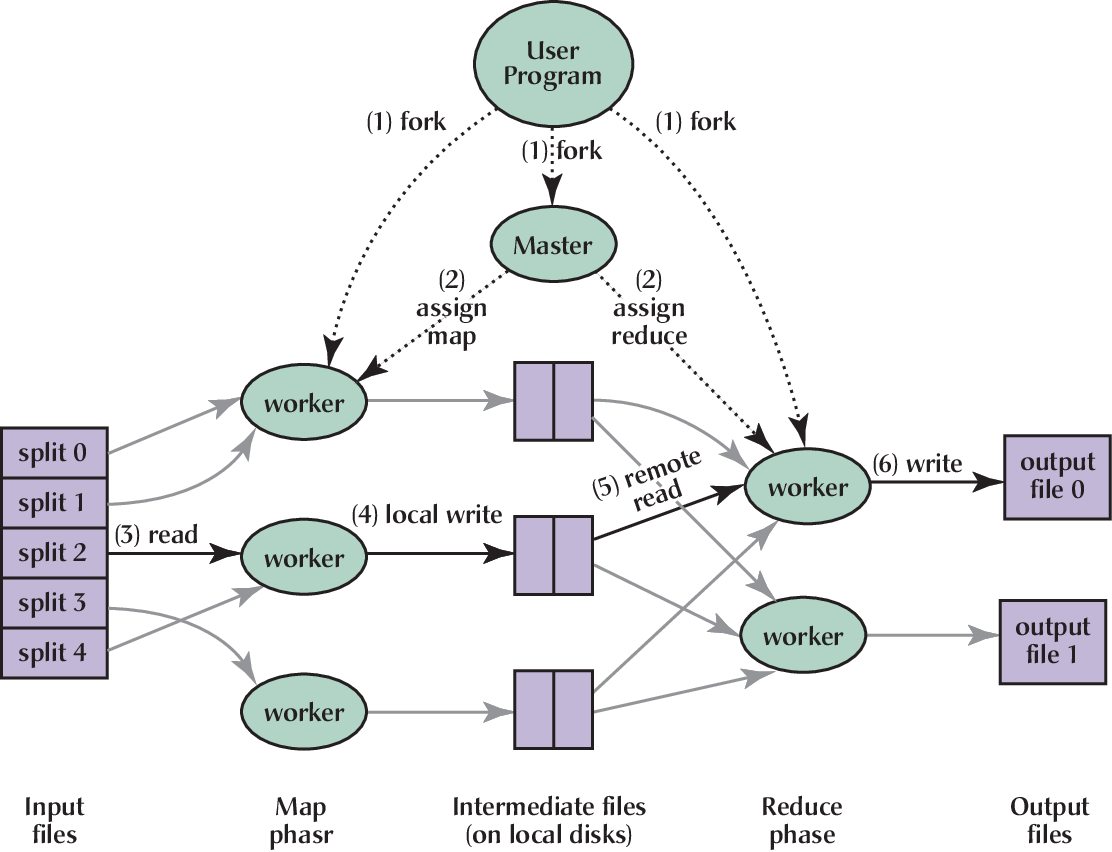
The framework of MapReduce (REF)
Lab 1
The task of Lab 1 is to implement the functionality of the Coordinator (i.e., Master) and Worker on the given framework. The experimental framework is written in Go language, and the RPC template code required has been provided. Therefore, we only need to learn GO language and MapReduce and understand the framework’s logic.
Design
First, it is necessary to clarify what information the Coordinator needs to maintain. Information about the tasks is necessary, including the corresponding files, start time, status, etc. Whether the information about the Worker needs to be maintained is a question that needs to be discussed. It seems that in many MapReduce systems, the Coordinator records the status of the Worker, the tasks it holds, and other information for task scheduling and error handling. However, in the simple framework of Lab 1, I believe that the information about the Worker does not need to be maintained and can be processed according to the flowchart shown below:

- The
Coordinatorreads the entire task, divides it into severalMaptasks, and prepares to assign them to theWorker. - The
Workerrequests a task throughGetTask, and theCoordinatorassigns a task from the idleMaptasks to theWorker, recording the start time of the task. - The
Coordinatorperiodically checks whether any tasks have timed out and, if so, returns them to the idleMaptask pool. - After the
Workercompletes the task, it reports the task result throughUpdateTask, and theCoordinatorremoves the task from the idleMaptask pool and records the necessary information for building theReducetask. - Repeat steps 2-4 until all
Maptasks are completed. - Based on the results of the
Mapphase, theCoordinatorbuilds theReducetask and prepares to assign it to theWorker. - Similar to steps 2-4, the
Workerreceives and executes the task, and theCoordinatorchecks for task timeouts and reassigns tasks. - After all
Reducetasks are completed, necessary work can be done before exiting.
Considering that the Worker that executes the task can manage its own state, the Coordinator doesn’t need to record information about the Worker. This is somewhat similar to process scheduling in an operating system, where each core takes tasks from the ready queue to execute, rather than the scheduler recording the status of each core. The advantage of this design is that the Coordinator only needs to maintain information about the tasks and wait for the Worker to initiate a request. If the Coordinator does not receive a report even after the Worker requests and assigns a task until it times out, it is considered that the Worker has made an error, and the task can be reassigned.
If we want to further implement the saving and restoring of intermediate task states, adding support for the UpdateTask function may be sufficient. There is still no need to maintain information about the Worker at the Coordinator.
Implementation summary
Debugging
The lab guide mentions using DPrintf for debugging. However, this function is not provided in the Lab 1 framework, so copying it from the framework of subsequent labs is a good choice.
However, it may be better to implement colored and graded logging output in future labs. We can consider implementing on in subsequent labs.
Worker
In my design, the structure of the Worker is straightforward: it continuously requests tasks in a loop and decides the next step based on whether it is Map, Reduce, or Exit. However, it should be noted that sometimes there are no idle tasks when the Worker requests a task, so it needs to wait for some time. I put this waiting time in the Coordinator and the Worker blocks at GetTask. Upon careful consideration, this design is not very reasonable, as it may result in the Coordinator assigning new tasks to a Worker that no longer exists after the Worker times out, which has a certain impact on overall performance.
Coordinator
There are two approaches to implementing the Coordinator:
- Use a big lock to synchronize all operations.
- Use a separate thread to perform all data operations and communicate with the thread through channels for all external interfaces.
The former implementation may be simpler, but Go seems to prefer using channels. Therefore, I chose the latter approach for implementation, and the general framework is shown in the following diagram:

The main processing logic of the Coordinator is in the separate thread process.
- The
GetTaskandUpdateTaskreceived by theCoordinatorare both notified toprocessthroughreqChan. Theprocessthen processes them and puts the new task intotaskChanfor response toGetTaskor updating the task status passed in byUpdateTask. - The
Coordinatormaintains a timer to check for tasks that may time out periodically. Initially, I thought it was only necessary to check when theWorkerrequested a task, so this check was triggered whenGetTaskwas called. However, sinceGetTaskis blocked at theCoordinatorin my implementation, the significance of this check is not very significant. - When the task update triggered by
UpdateTaskcauses the entire system’s state to change fromMaptoReduceand then toExit, a signal is sent todoneChanfor the final exit.
Pitfalls
The interaction between the Worker, the Coordinator, and the management of their respective states is the difficult part of the implementation. If done incorrectly, it is easy to cause deadlocks (or livelocks? I haven’t analyzed it carefully). Then you will encounter situations where the tests cannot be passed, but you don’t know why (lol).
It is very necessary to use DPrintf to print logs to help understand what your implemented system is doing.
Miscellaneous
This is my first time using the Go language. While trying to implement Lab 1, I always wanted to write functions like .filter() and .forEach(), but Go does not provide these functions, and you need to use for loops to achieve the desired functionality. Strangely, a language that provides various network-related tools in its standard library does not provide some basic methods. Moreover, Go’s syntax has many “appearance” differences from Rust and JavaScript, which I am familiar with, giving me a feeling of using a dialect of C++.
In short, I don’t really like Go.